By Camille D., Age 17
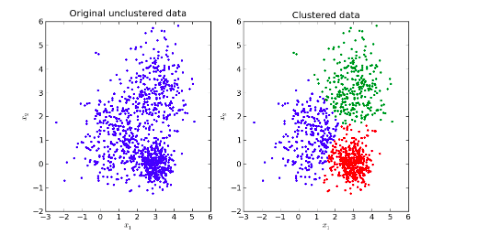
K-means clustering is one of the most widely used and straightforward machine learning algorithms. Its goal is to find groups or clusters within a set of data, the number of which is denoted by k. It is an iterative algorithm that partitions a dataset into subgroups such that the subgroups don’t overlap and each data point only has only one unique subgroup. Each cluster has a centroid, or its own arithmetic mean of all of its data points. Centroids can be used to label new data.
K-means clustering allows the user to find groups that have been created organically, rather than groups defined before the data comes up, making k-means an unsupervised machine-learning algorithm. The value of k itself, however, must be pre-defined.

Some applications of k-means clustering can be defining personalities based on interests, determining characteristics of images based on stages or categories of a disease, and dividing by activities on a mobile application or a website.
The two inputs to the algorithm are the value for k and the dataset. Centroids are first initialized by shuffling the dataset and then randomly selecting k data points to be centroids for each cluster. The algorithm then follows two iterative steps:
1. Data, centroid assignment

2. Centroid updating

Steps one and two are repeated until a terminal case is met (there is no change to the centroids, assignments of data points to clusters isn’t changing).
Something to note about choosing the value of k is that we can use something called the Elbow Method. For example, start by running k-means on a dataset for a range of values of k (i.e. 2 to 10), and for each value of k, calculate the sum of squared error (average within-cluster distance to centroid). If we were to plot the SSE for each value of k on a line plot, and we detect an inflection point, we would use the value of k at which that inflection point occurs. Here is an example of such a plot, showing the ideal value for k:

An example of k-means is as follows: suppose we have four objects that each have two attributes, and we want to group these objects into k = 2 clusters based on the two attributes.

We can represent these as coordinates in an attribute space below:

Suppose we want to use Object A and B as the centroids. Thus, the coordinates of the centroids are (2, 3) and (1, 4).

Next, use Euclidean distance to calculate the cluster centroid to each individual object. We will obtain a distance matrix at iteration 0:

Each column of this matrix represents the objects successively. The first row represents that object’s distance to Object A on the plot, and the second represents that object’s distance to Object B on the plot. Next, we do the actual clustering based on the minimum distance. We will define two clusters for each centroid as C1 and C2. For example, since Object A’s distance to itself is obviously smaller than Object B’s distance to Object A, Object A will belong to the C1.
Let’s define a new Group matrix, where the columns again correspond to each object, but their values will be assigned to either 0 or 1 based on whether they are in C1or C2. The rows correspond to each cluster successively.

Now that we have assigned data points to their clusters, we can compute the new centroids. Since C2 has only one member, which is Object B (1, 4) itself, the centroid will remain (1, 4). C1, however, has three members, so its new centroid will be the average coordinate of its three members:
![]()
We continue these two steps until the terminal case is reached, which, in this case, occurs when the number of elements in C1 is equal to the number of elements in C2.